
Warstwa cache potrafi odciążyć bazę, skrócić p95 odpowiedzi, czyli czas, który nie spowalnia 95 proc. zapytań, i sprawić, że aplikacja przestaje niepotrzebnie mielić tych samych danych przy każdym żądaniu. Dobrze skonfigurowany redis cache jest jednym z najprostszych sposobów, by przyspieszyć odczyty bez przebudowy całej architektury. W tym artykule pokazuję, kiedy to ma sens, jak działa w praktyce, które ustawienia są krytyczne i jakie błędy najczęściej psują efekt.
Kluczowe informacje, które warto znać przed wdrożeniem cache
- Cache najbardziej pomaga tam, gdzie odczytów jest wyraźnie więcej niż zapisów.
- Najbezpieczniejszym startem zwykle jest wzorzec cache-aside.
- TTL, limit pamięci i polityka usuwania kluczy są ważniejsze niż sama instalacja serwera.
- Cache nie może być jedynym źródłem prawdy dla krytycznych danych.
- Bez monitoringu hit rate i eviction łatwo uzyskać szybki, ale niestabilny system.
Czym jest cache Redis i kiedy naprawdę pomaga
Redis działa w pamięci, więc odczyt danych odbywa się bez czekania na wolniejszy dysk albo zewnętrzną bazę. W praktyce oznacza to krótszy czas odpowiedzi dla endpointów, które często zwracają te same informacje: listy produktów, konfiguracje, sesje użytkowników, tokeny, wyniki kosztownych zapytań albo dane do dashboardów.
Najlepiej sprawdza się tam, gdzie dane mogą być chwilowo „nieco starsze” bez szkody dla biznesu. Jeśli każda zmiana musi być widoczna natychmiast i bez żadnego marginesu błędu, cache przestaje być prostym przyspieszeniem, a zaczyna wymagać bardzo ostrej strategii unieważniania.
To ważne rozróżnienie, bo w projektach sieciowych i internetowych nie chodzi tylko o szybkość, ale też o przewidywalność pod obciążeniem. I właśnie od tego zależy wybór modelu pracy z cache.
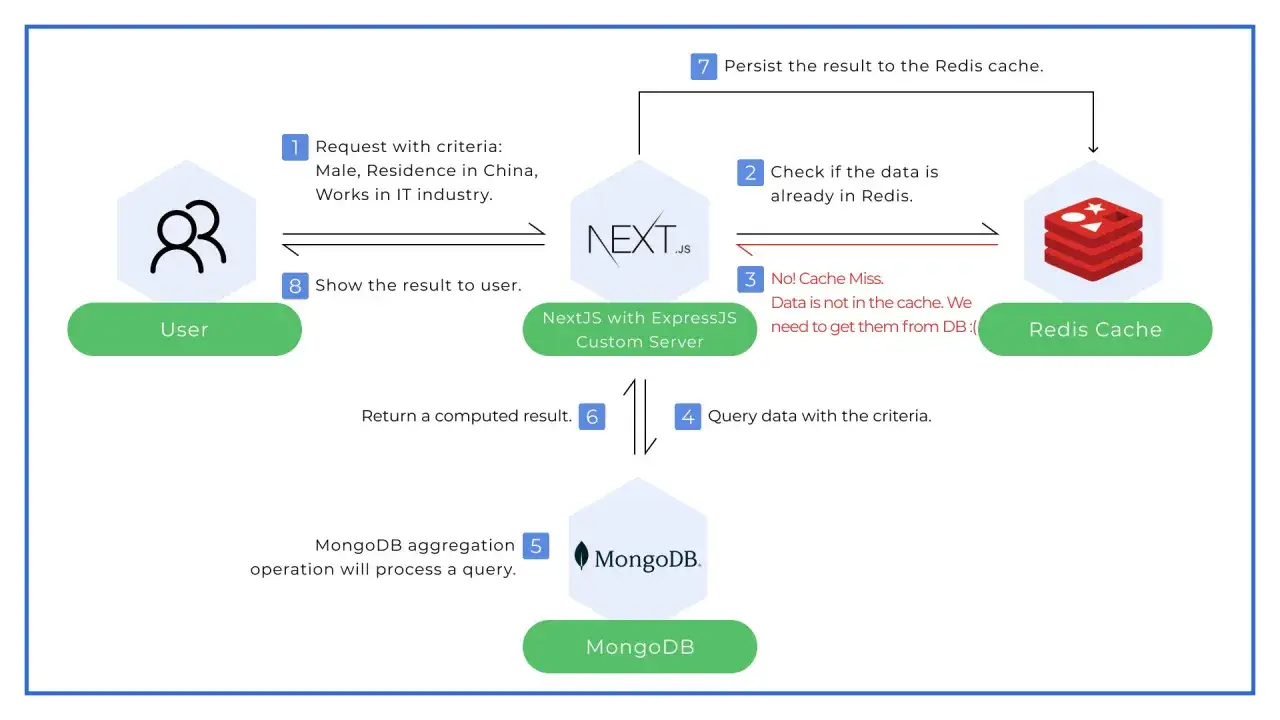
Jak działa cache w ścieżce zapytania
Najprostszy scenariusz wygląda tak: aplikacja najpierw pyta cache, a dopiero potem sięga do bazy, jeśli klucza nie ma. Taki brak to cache miss; trafienie to cache hit. Przy hitach aplikacja dostaje odpowiedź niemal od razu, a przy missie płaci koszt pobrania danych z wolniejszego źródła i zapisania ich z powrotem do cache.
W praktyce działa to najlepiej dla danych, które można odtworzyć z systemu źródłowego. Jeżeli rekord zniknie z cache albo zostanie usunięty przez politykę pamięci, aplikacja po prostu pobiera go ponownie. To dlatego cache jest świetny jako przyspieszenie, ale słaby jako jedyne miejsce przechowywania informacji.
Warto też pamiętać o czasie życia klucza. Redis pozwala ustawić wygasanie, a najczęściej robi się to poleceniem EXPIRE. Komenda TTL zwraca pozostały czas życia w sekundach, a PTTL podaje go z dokładnością do milisekund. Jeśli klucz nie ma ustawionego wygaśnięcia, wynik sygnalizuje brak timeoutu; jeśli klucza nie ma, wynik wskazuje, że został już usunięty.
Ta ścieżka odczytu prowadzi prosto do kolejnego pytania: jaki model cache wybrać, żeby nie skomplikować aplikacji bardziej niż trzeba?
Który model cache wybrać
Nie każdy zespół potrzebuje tego samego wzorca. Wybór zależy od tego, czy ważniejsza jest prostota, spójność, czy maksymalna wydajność zapisów. Poniżej zestawiam modele, które realnie spotyka się w aplikacjach webowych i API.
| Model | Kiedy ma sens | Największa zaleta | Ryzyko albo koszt |
|---|---|---|---|
| Cache-aside | Gdy odczytów jest więcej niż zapisów, a pominięcia cache są akceptowalne | Prosty start i pełna kontrola po stronie aplikacji | Trzeba samodzielnie dbać o unieważnianie danych |
| Query caching | Gdy chcesz przyspieszyć powtarzalne proste zapytania SQL lub stopniowo iść w stronę mikroserwisów | Minimalna zmiana w sposobie pracy z danymi | Łatwo zamienić prosty cache w „magazyn wszystkiego” |
| Write-through | Gdy spójność między cache a bazą jest ważniejsza niż koszt zapisu | Dane trafiają do cache i do bazy w sposób synchroniczny | Każdy zapis kosztuje więcej i wydłuża ścieżkę operacji |
| Write-behind | Gdy priorytetem jest odciążenie zapisów i aplikacja może poczekać na aktualizację bazy | Bardzo dobra wydajność ścieżki zapisu | Większe ryzyko chwilowej niespójności danych |
| Cache prefetching | Gdy strumień danych ma być stale synchronizowany przed odczytem | Dane są już w cache, zanim aplikacja ich potrzebuje | Ma sens głównie tam, gdzie przepływ jest dobrze przewidywalny |
Jeśli mam wskazać domyślne bezpieczne podejście, to zaczynam od cache-aside. Daje dobry balans między prostotą a kontrolą, a przy tym nie wymusza synchronizowania każdej zmiany po obu stronach od razu. Write-through wybieram dopiero wtedy, gdy spójność danych jest ważniejsza niż koszty zapisu, a write-behind wtedy, gdy priorytetem staje się odciążenie ścieżki zapisu.
Prefetching traktuję bardziej jako rozwiązanie dla uporządkowanych, stałych przepływów danych niż dla każdej zwykłej aplikacji. Gdy model jest już wybrany, trzeba dopiero ustawić pamięć i zasady usuwania kluczy.
TTL, limit pamięci i polityka usuwania
Tu najłatwiej popełnić błąd, bo samo „postawienie Redis” niczego nie gwarantuje. Trzeba świadomie zdecydować, jak długo dane mają żyć, ile pamięci cache może zająć i co ma się stać, gdy miejsca zacznie brakować.
- TTL - ustawiaj dla danych, które mogą się zestarzeć. Jeśli klucz ma realny cykl życia, cache powinien to odzwierciedlać, a nie udawać wieczność.
- maxmemory - ustaw limit zamiast liczyć na to, że pamięć „sama się nie skończy”. W praktyce to podstawowy bezpiecznik dla produkcji.
-
Polityka usuwania - najczęściej spotkasz
allkeys-lru,allkeys-lfu,volatile-lru,volatile-lfu,volatile-ttloraznoeviction. - Persistence - jeśli Redis ma służyć wyłącznie jako cache, trwałość danych można wyłączyć; jeśli pełni też inną rolę, decyzja wymaga osobnej analizy.
- Bufory replikacji i zapisu - przy replikacji albo persistence zostaw trochę RAM wolnego, bo ta część pamięci nie zawsze zachowuje się tak, jak intuicyjnie zakładamy.
| Polityka | Co robi | Kiedy ma sens |
|---|---|---|
allkeys-lru |
Usuwa najmniej ostatnio używane klucze | Gdy liczy się świeżość i ruch ma wyraźny trend „gorących” danych |
allkeys-lfu |
Usuwa najmniej często używane klucze | Gdy część danych regularnie wraca, a część jest tylko chwilowa |
volatile-lru / volatile-lfu
|
Działa tylko na kluczach z TTL | Gdy cache zawiera także dane bez wygasania |
volatile-ttl |
Usuwa najpierw klucze z najkrótszym czasem do wygaśnięcia | Gdy chcesz zachować te dane, które jeszcze długo będą użyteczne |
noeviction |
Nie usuwa kluczy, tylko zgłasza błąd przy braku miejsca | Gdy wolisz błąd niż ciche wyrzucanie danych z pamięci |
To są ustawienia, które bezpośrednio wpływają na stabilność. W dobrze działającym cache nie chodzi o to, by nigdy nic nie znikało, tylko o to, by znikało przewidywalnie i bez zaskoczeń dla aplikacji. Z tym w tle łatwiej zrozumieć, jakie błędy popełnia się najczęściej.
Najczęstsze błędy, które psują efekt
Największe problemy rzadko biorą się z samej technologii. Zwykle wynikają z tego, że cache wdrożono bez jasnej odpowiedzi na pytanie: co dokładnie ma przyspieszać i jak długo może pozostać aktualne.
- Cacheowanie wszystkiego - jeśli nie wiesz, które dane realnie wracają w ruchu, zapełniasz pamięć treściami bez wartości.
- Brak strategii invalidacji - po zapisie w bazie cache musi wiedzieć, co unieważnić, inaczej zacznie serwować stare dane.
- Zbyt długi TTL - im bardziej zmienne dane, tym krótszy czas życia klucza; inaczej oszczędzasz milisekundy kosztem poprawności.
- Jednoczesne wygaśnięcia - jeśli wiele kluczy kończy życie w tej samej chwili, dodaj losowy margines do TTL, żeby uniknąć skoków ruchu do bazy.
-
Nieprzemyślana polityka usuwania - złe
evictionpotrafi wyrzucić właśnie te dane, które powinny zostać w pamięci najdłużej. - Założenie, że cache zastąpi bazę - pamięć podręczna ma przyspieszać, nie przechowywać prawdy biznesowej.
Najbardziej kosztowny błąd widzę zwykle wtedy, gdy zespół patrzy tylko na liczbę trafień w cache, a nie na świeżość danych i zachowanie systemu przy skoku ruchu. Lepiej mieć prosty cache z dobrą invalidacją niż sprytny mechanizm, który w czasie piku zaczyna podawać nieaktualne odpowiedzi albo zasypywać bazę lawiną zapytań. Następny krok to wdrożenie tego w sposób, który da się utrzymać w produkcji.
Jak wdrożyć go rozsądnie w projekcie
W mojej praktyce najlepiej działa podejście etapowe. Zamiast od razu przenosić cały ruch do cache, wybieram kilka najdroższych i najczęściej odczytywanych ścieżek, a potem sprawdzam, czy rzeczywiście zyskują na odciążeniu.
- Wybierz kilka endpointów o największym ruchu odczytowym.
- Zmierz bazowy czas odpowiedzi i obciążenie bazy.
- Ustal klasę danych i dopasuj do niej TTL.
- Wdróż cache-aside i zacznij logować hit rate oraz miss rate.
- Dodaj unieważnianie przy zapisie albo zmianie wersji klucza.
- Ustal
maxmemoryi politykęeviction. - Testuj zachowanie przy piku ruchu i przy kończącej się pamięci.
Bez metryk szybko nie wiesz, czy naprawdę przyspieszasz aplikację, czy tylko przenosisz problem w inne miejsce. Minimum to hit rate, p95 czasu odpowiedzi, liczba evictions i zużycie pamięci. Jeśli te wskaźniki są pod kontrolą, cache przestaje być eksperymentem, a staje się normalną częścią architektury.
Przy większych systemach dochodzi jeszcze kwestia odporności i skalowania. Jeżeli cache staje się krytyczny dla działania serwisu, trzeba wcześniej zaplanować replikację, obserwowalność i sposób odtwarzania danych po awarii, zamiast czekać, aż wymusi to produkcja.
Co decyduje o tym, że cache pozostaje szybki także po miesiącach
Jeżeli miałbym zostawić jedną zasadę, powiedziałbym tak: cache ma przyspieszać system, a nie zastępować myślenie o danych. Najlepiej działa wtedy, gdy od początku wiadomo, co cacheujemy, jak długo, po czym to unieważniamy i co robimy, gdy pamięć się zapełni.
- Dobieraj dane według częstotliwości odczytu, nie według intuicji.
- Ustal TTL i politykę usuwania przed wdrożeniem na produkcję.
- Monitoruj hit rate, evictions i p95 odpowiedzi.
- Nie trzymaj w cache informacji, które muszą być natychmiast zgodne z bazą.
Wtedy warstwa cache zaczyna realnie skracać odpowiedzi aplikacji, odciąża bazę i poprawia komfort użytkownika. Właśnie tak powinien działać dobry cache Redis: cicho, przewidywalnie i bez dokładania zespołowi pracy w tle.