
Budowa bazy danych zaczyna się od pytania, jakie dane będą w niej żyły, kto będzie z nich korzystał i jak ruch z aplikacji przejdzie przez sieć. Pokażę, jak stworzyć bazę danych tak, żeby od początku miała sensowny model, poprawne kodowanie, oddzielne konto aplikacji i bezpieczny dostęp z internetu albo prywatnej sieci. Skupię się na praktyce, bo właśnie na tym etapie najłatwiej uniknąć kosztownych poprawek.
Najważniejsze decyzje zapadają przed pierwszym poleceniem SQL
- Najpierw wybierz silnik pod konkretny scenariusz, a dopiero potem twórz strukturę.
- Model danych rysuje się przed tabelami, nie po nich.
- Dla aplikacji internetowej baza powinna być w prywatnej sieci, a połączenia szyfrowane.
- Konto aplikacji ma mieć tylko te uprawnienia, które są naprawdę potrzebne.
- Backup ma sens dopiero wtedy, gdy potrafisz go odtworzyć.
- Indeksy dodawaj tam, gdzie faktycznie filtrujesz, sortujesz lub łączysz tabele.
Zacznij od tego, do czego baza ma służyć
W praktyce nie zaczynam od polecenia CREATE DATABASE, tylko od odpowiedzi na jedno pytanie: czy to ma być baza dla bloga, sklepu, panelu administracyjnego, API, czy może małego prototypu. Od tego zależy silnik, sposób przechowywania danych, model uprawnień i to, jak bardzo trzeba uważać na ruch sieciowy. Dla prostych stron najczęściej wystarcza MySQL albo PostgreSQL, w środowiskach Microsoft naturalnym wyborem bywa SQL Server, a SQLite zostawiam raczej do lokalnych testów i małych aplikacji, nie do publicznej usługi z wieloma użytkownikami.
| Scenariusz | Najczęstszy wybór | Dlaczego to działa |
|---|---|---|
| Blog, strona firmowa, prosty CMS | MySQL lub PostgreSQL | Łatwe wdrożenie, dobre wsparcie hostingu i frameworków |
| Aplikacja webowa z API i większą liczbą relacji | PostgreSQL | Świetnie radzi sobie z relacjami, indeksami i regułami spójności |
| Projekt oparty o ekosystem Microsoft | SQL Server | Naturalnie pasuje do Windows, .NET i narzędzi administracyjnych |
| Prototyp, test lokalny, pojedynczy użytkownik | SQLite | Nie wymaga osobnego serwera i jest szybka do startu |
Jeśli wybór silnika zrobisz spokojnie na początku, reszta układanki staje się prostsza. Gdy to jest już jasne, można przejść do rzeczy ważniejszej niż sama baza, czyli do modelu danych.
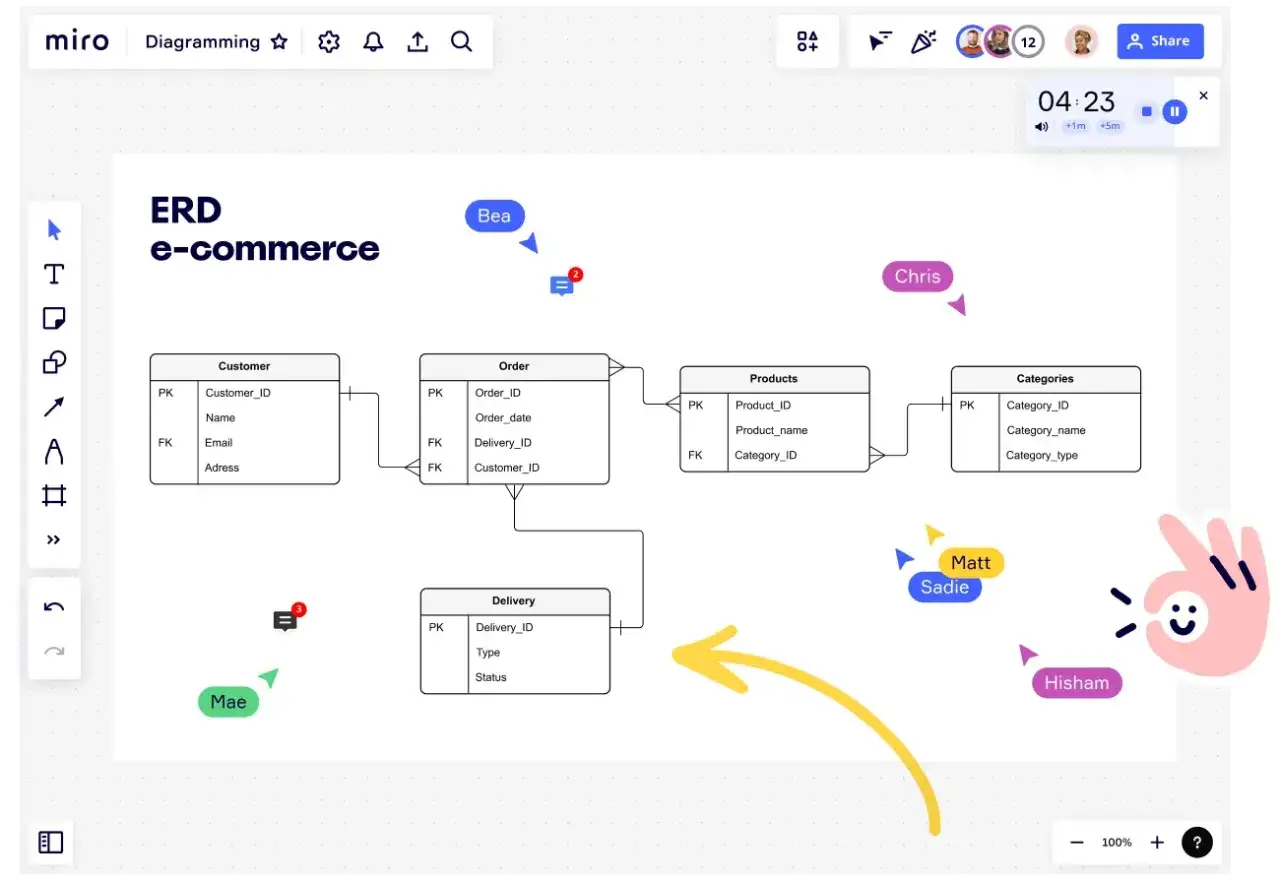
Najpierw narysuj model danych, dopiero potem twórz tabele
Największy błąd początkujących polega na tym, że chcą „po prostu założyć bazę”, a dopiero później zastanawiają się, co w niej ma być. Ja robię odwrotnie: najpierw wypisuję encje, czyli główne byty biznesowe, potem relacje między nimi, a na końcu dopiero przekładam to na tabele i klucze. W aplikacji internetowej zwykle pojawiają się przynajmniej użytkownicy, sesje, zamówienia, produkty, płatności albo logi aktywności.
Co warto rozpisać na kartce
- Encje - na przykład użytkownik, zamówienie, produkt, wpis na blogu.
- Relacje - kto do czego należy, co jest przypisane do czego i ile rekordów może się łączyć.
- Klucze główne - identyfikatory rekordów, które nie powinny się powtarzać.
- Klucze obce - pola spinające tabele w logiczną całość.
- Pola unikalne - na przykład email, numer zamówienia albo login.
Przeczytaj również: Starlink w Polsce - Cena, działanie i czy zastąpi światłowód?
Normalizacja bez przesady
Przy projektowaniu bazy często wraca pojęcie normalizacji, czyli porządkowania danych tak, aby nie dublować ich bez potrzeby. Najprościej mówiąc: jedna wartość w jednej kolumnie i jeden fakt w jednym miejscu. Jeśli trzymasz listę tagów w jednym polu tekstowym albo wpisujesz dane adresowe klienta w kilku tabelach bez planu, to bardzo szybko zrobi się bałagan. Z drugiej strony nie warto rozbijać wszystkiego do granic absurdu, bo potem zapytania są trudne, a aplikacja zaczyna się męczyć na joinach. Dobre rozwiązanie to zwykle rozsądny balans między porządkiem a praktycznością.
Gdy model jest już zapisany, dopiero wtedy ma sens tworzenie samej bazy i pierwszych obiektów, bo wiesz, co naprawdę chcesz w niej trzymać.
Jak utworzyć bazę krok po kroku
W praktyce kolejność jest prosta: baza, użytkownik, uprawnienia, tabele, indeksy i migracje. W panelu hostingu wygląda to inaczej niż w terminalu, ale decyzje są te same. Najpierw zakładasz pusty kontener na dane, potem tworzysz konto aplikacji i dopiero na końcu dodajesz strukturę.
- Utwórz pustą bazę z kodowaniem UTF-8.
- Załóż osobnego użytkownika dla aplikacji.
- Nadaj temu użytkownikowi tylko potrzebne uprawnienia.
- Utwórz tabele i relacje między nimi.
- Dodaj indeksy tam, gdzie baza będzie często filtrowana.
- Zapisz schemat w migracjach, żeby dało się go odtworzyć.
Przykład dla MySQL:
CREATE DATABASE sklep CHARACTER SET utf8mb4 COLLATE utf8mb4_polish_ci;
CREATE USER 'sklep_app'@'10.%' IDENTIFIED BY 'mocne_haslo';
GRANT SELECT, INSERT, UPDATE, DELETE ON sklep.* TO 'sklep_app'@'10.%';Przykład dla PostgreSQL:
CREATE DATABASE sklep ENCODING 'UTF8';
CREATE ROLE sklep_app LOGIN PASSWORD 'mocne_haslo';
GRANT CONNECT ON DATABASE sklep TO sklep_app;Jeśli aplikacja działa na tym samym serwerze, ograniczam dostęp do localhost. Jeśli łączy się przez sieć, pilnuję, żeby konto było przypięte tylko do właściwej podsieci lub adresów serwera aplikacyjnego. Ten detal robi ogromną różnicę, kiedy baza później zaczyna obsługiwać ruch z internetu lub z chmury.
Dostęp przez sieć ustaw tak, by nie wystawić bazy światu
Baza danych używana przez aplikację webową prawie nigdy nie powinna mieć publicznego, szeroko otwartego dostępu. Najbezpieczniejszy układ to prywatna sieć, serwer aplikacyjny z dozwolonym dostępem i osobne połączenie administracyjne tylko dla ludzi, którzy naprawdę muszą wejść do środka. W praktyce oznacza to firewall, reguły sieciowe, TLS i brak „na wszelki wypadek otwartego portu”.
| Element | Co ustawiam | Po co |
|---|---|---|
| Firewall / reguły sieciowe | Wpust tylko z adresów serwera aplikacji lub z VPN | Ograniczenie powierzchni ataku |
| TLS | Szyfrowanie połączenia między aplikacją a bazą | Ochrona danych i poświadczeń w tranzycie |
| Listen address / bind | Nasłuch tylko na interfejsie prywatnym | Baza nie wystawia się na cały internet |
| Pula połączeń | Stała warstwa obsługująca wiele krótkich requestów | Mniej kosztownych połączeń i lepsza stabilność pod ruchem |
Na poziomie portów najczęściej spotkasz 3306 dla MySQL, 5432 dla PostgreSQL i 1433 dla SQL Server, ale sama liczba portu nie ma znaczenia, jeśli firewall przepuszcza ruch z całego świata. Przy aplikacjach internetowych lepiej myśleć o bazie jak o usłudze wewnętrznej, a nie o czymś, co ma być łatwe do znalezienia z zewnątrz.
Gdy sieć jest już spięta, trzeba jeszcze dopilnować bezpieczeństwa danych i planu odtwarzania, bo awaria przy ruchu internetowym zwykle kosztuje więcej niż sam błąd konfiguracji.
Bezpieczeństwo i kopie to część projektu, nie dodatek
Jeśli mam jedną zasadę, to taką: backup bez testu odtwarzania jest tylko nadzieją. W praktyce zaczynam od rozdzielenia kont: administracyjne ma służyć do zarządzania, a konto aplikacji tylko do pracy z danymi. Hasła i klucze trzymam poza repozytorium, najlepiej w zmiennych środowiskowych albo w managerze sekretów, a nie w pliku konfiguracyjnym wrzuconym do kodu.
- Codzienny backup - minimum dla większości produkcyjnych baz.
- Częstsze kopie lub ciągły zapis zmian - gdy dane zmieniają się intensywnie, na przykład w sklepie lub systemie rezerwacji.
- Odtwarzanie testowe raz w miesiącu - żaden backup nie daje spokoju, jeśli nie sprawdziłeś restore.
- Kopia poza głównym serwerem - osobny dysk, inna maszyna albo inny region chmury.
- Szyfrowanie kopii - szczególnie wtedy, gdy backup opuszcza jedną strefę bezpieczeństwa.
W internetowych systemach ważne są też limity dostępu. Nie przyznaję aplikacji pełnych uprawnień tylko dlatego, że „tak szybciej działa”, bo to klasyczny skrót, który później kończy się problemami przy wycieku lub błędzie w kodzie. Im większy ruch i im więcej integracji, tym bardziej opłaca się zachować zasadę najmniejszego niezbędnego dostępu.
Kiedy bezpieczeństwo i kopie są ustawione, łatwiej zobaczyć inne słabe punkty, czyli rzeczy, które najczęściej psują pierwszy projekt.
Najczęstsze błędy przy pierwszej bazie
Najwięcej problemów widzę wtedy, gdy ktoś traktuje bazę jak magazyn „na wszystko”. Jedna wielka tabela, brak kluczy obcych, uprawnienia administratora dla aplikacji i publiczny port to przepis na chaos, który przez chwilę działa, a potem zaczyna kosztować godziny pracy. W projektach internetowych takie błędy wychodzą szybciej, bo baza od razu dostaje ruch z sieci, a nie tylko lokalne testy.
- Jedna tabela do wszystkiego - trudna do utrzymania, wolna i podatna na błędy.
-
Brak indeksów - szczególnie na polach filtrowania, sortowania i łączenia, takich jak
user_idczycreated_at. - Publiczny dostęp bez ograniczeń - baza nie powinna słuchać całego internetu, jeśli nie ma ku temu bardzo dobrego powodu.
- Złe kodowanie - bez UTF-8 szybko pojawiają się problemy z polskimi znakami i danymi z formularzy.
- Brak migracji - schemat staje się niepowtarzalny, a wdrożenia robią się ręczne i ryzykowne.
- Backup bez odtworzenia - kopia istnieje tylko na papierze, dopóki nie sprawdzisz, że działa przywracanie.
Jeżeli jedna kolumna regularnie pojawia się w warunku WHERE albo w JOIN, zwykle zasługuje na indeks. To prosty nawyk, który bardzo często daje większy efekt niż późniejsze kombinowanie z „optymalizacją” całej bazy na ślepo.
Po wyłapaniu tych błędów zostaje już tylko domknięcie projektu tak, żeby baza była gotowa na rozwój, a nie tylko na pierwszy dzień działania.
Dobre nawyki na start, które oszczędzają tygodnie pracy
Ja lubię zostawiać projekt w stanie, w którym kolejna osoba albo przyszła wersja mnie samego może go zrozumieć bez zgadywania. Dlatego od początku zapisuję migracje w repozytorium, pilnuję spójnych nazw tabel i kolumn, przygotowuję dane testowe do środowiska lokalnego i monitoruję czas odpowiedzi zapytań, zanim zaczną boleć użytkowników. Jeśli baza ma obsługiwać ruch z internetu, to takie drobiazgi bardzo szybko przestają być drobiazgami.
- Migracje w repo - schemat jest wersjonowany, a nie odtwarzany z pamięci.
- Dane startowe - przyspieszają testowanie i pracę programistów.
- Monitoring slow query - pomaga znaleźć zapytania, które naprawdę spowalniają system.
- Alert na backup - brak kopii wykrywasz od razu, a nie po awarii.
- Krótka dokumentacja - wystarczy kilka zdań o strukturze, użytkownikach i sposobie odtwarzania.
Jeśli miałbym streścić cały proces jednym zdaniem, powiedziałbym tak: baza danych powinna być zaprojektowana pod realny ruch, ograniczony dostęp i łatwe odtworzenie, a nie tylko pod szybkie uruchomienie. Taki porządek na starcie zwykle oszczędza najwięcej czasu wtedy, gdy projekt zaczyna rosnąć.